


【保姆级教程】DeepSeek R1+RAG,基于开源三件套10分钟构建本地AI知识库

xueqi
一、总体方案
目前在使用 DeepSeek 在线环境时,页面经常显示“服务器繁忙,请稍后再试”,以 DeepSeek R1 现在的火爆程度,这个状况可能还会持续一段时间,所以这里给大家提供了 DeepSeek R1 +RAG 的本地部署方案。最后实现的效果是,结合本地部署的三个开源工具,包括 1Panel、Ollama、MaxKB,可以快速搭建一个本地知识库。以下总体方案及说明如下: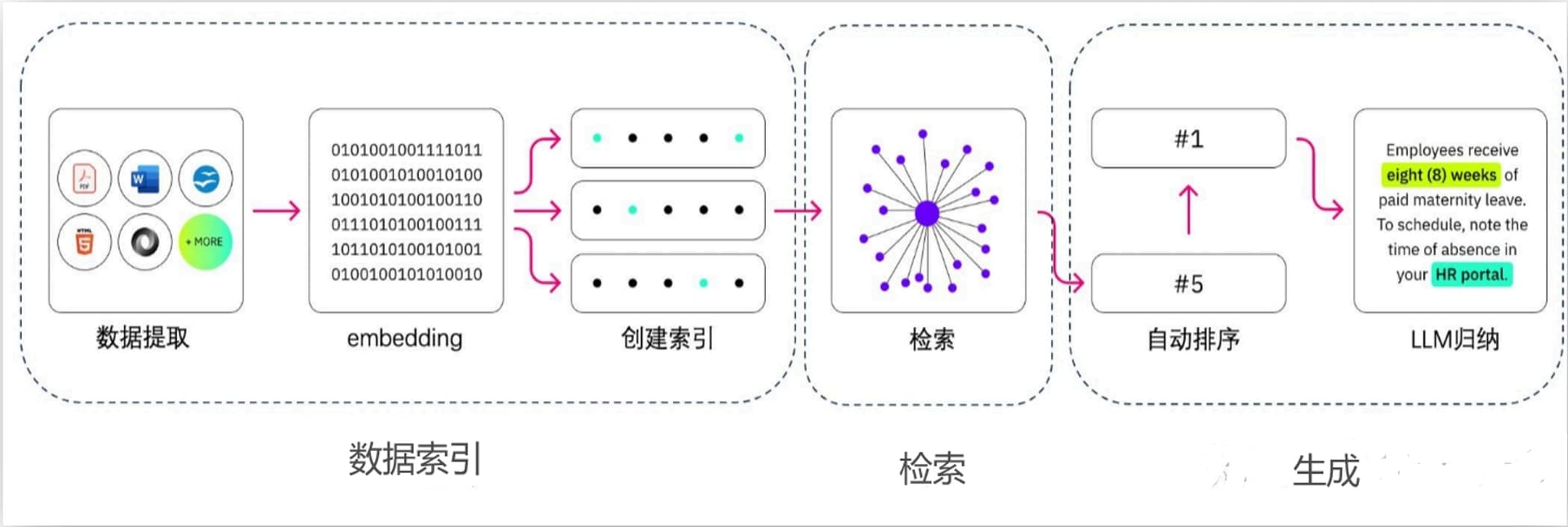
-
检索(Retrieval):在这个阶段,模型会从预先构建的大规模数据集中检索出与当前任务最相关的信息。这些数据集可以是文档、网页、知识库等。
-
生成(Generation):在检索到相关信息后,模型会使用这些信息来生成答案或完成特定的语言任务。这个阶段通常涉及到序列生成技术,如基于 Transformer 的模型。

2.1 第一步:准备服务器
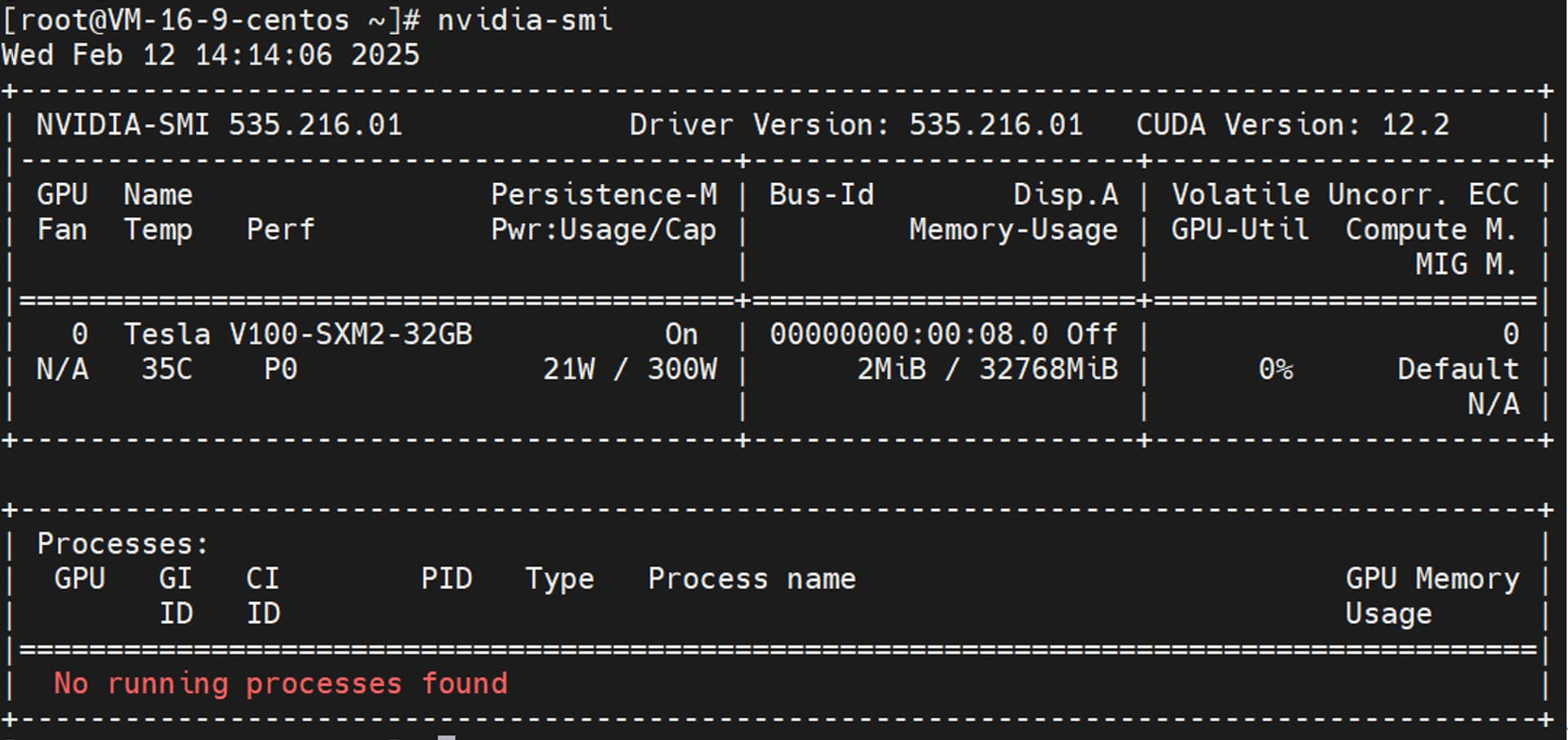
首先我们需要准备一台本地 GPU 服务器,其中 GPU 主要为 DeepSeek R1 大模型提供资源,本操作步骤全部基于腾讯云的 GPU 服务器,大家可以根据自己具体情况选择本地服务器。腾讯云的 GPU 服务器在开机时,默认会自动安装好 Nvidia GPU 驱动。
2.2 第二步:安装 1Panel
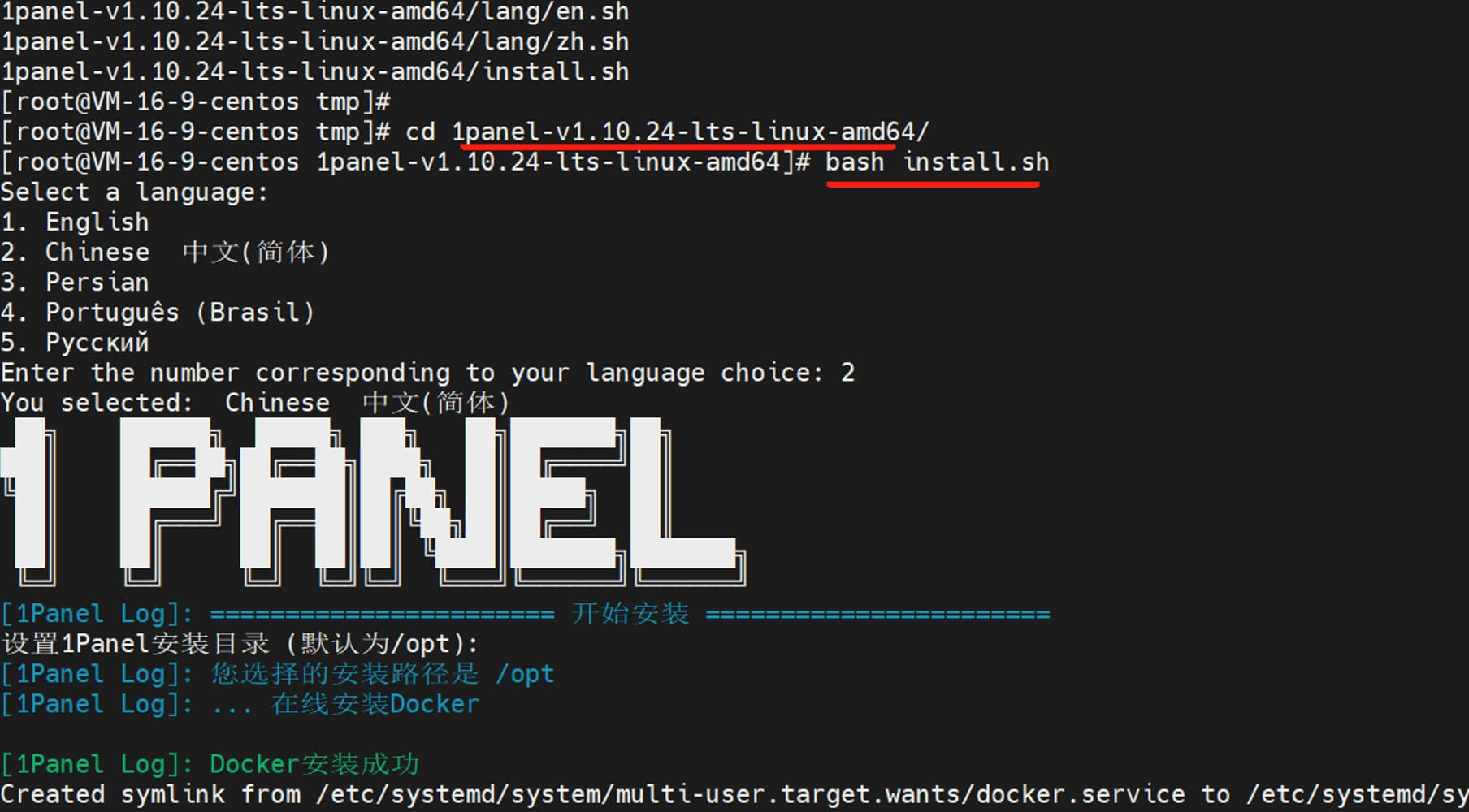
浏览器访问 https://community.fit2cloud.com/#/products/1panel/downloads,下载好 1Panel 离线包安装包,并上传到腾讯云服务器的 /tmp 目录,执行 tar -xvf 命令,解压安装包。
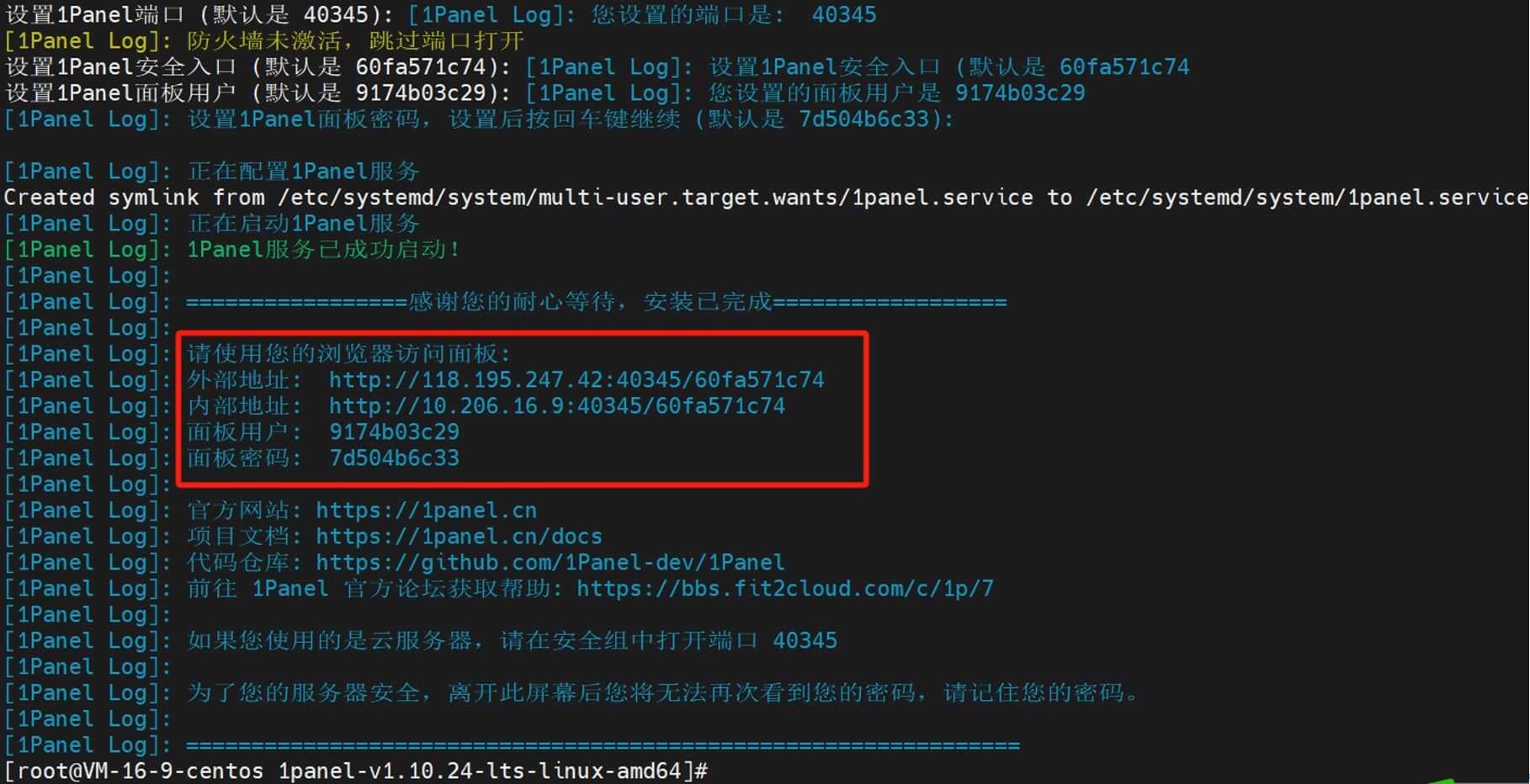
安装成功后,日志会显示 1Panel 服务的访问地址信息。
为方便 1Panel 安装其它开源工具时,能快速下载 Docker 镜像,这里需要配置 Docker 镜像加速器。/etc/docker/daemon.json 配置文件内容如下:
{ "registry-mirrors": [ "https://docker.1ms.run", "https://proxy.1panel.live", "https://9f73jm5p.mirror.aliyuncs.com", "https://docker.ketches.cn" ] }/etc/docker/daemon.json 配置文件修改,需要 重启 Docker 服务。
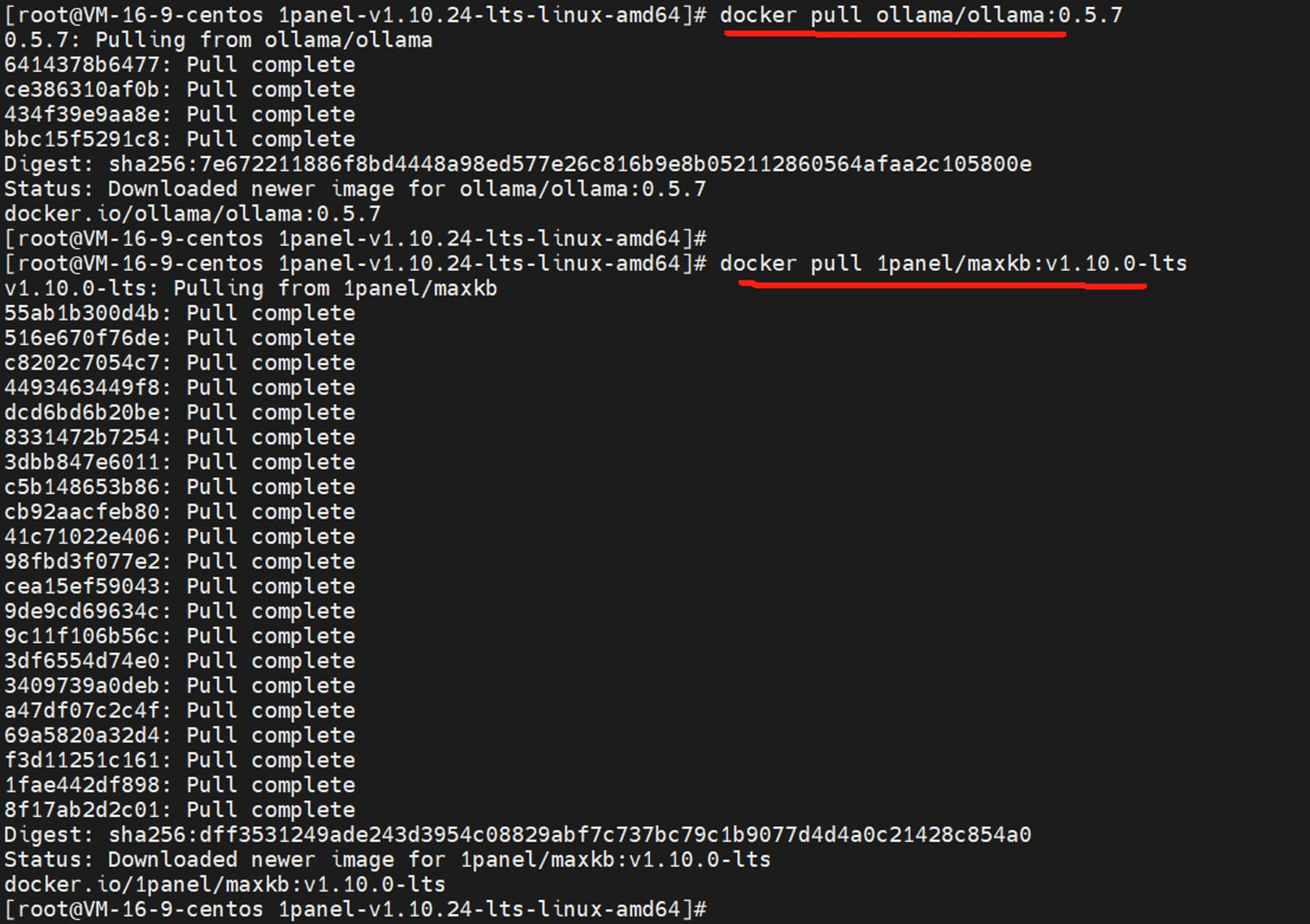
需要注意的是,Ollama 容器如果想使用服务器的 GPU 资源,操作系统需要提前安装 NVIDIA Container Toolkit,这是 NVIDIA 容器工具包。以 CentOS 7.9 操作系统为例,安装步骤如下:
1、添加 NVIDIA 的 GPG 密钥和仓库:distribution=$(. /etc/os-release;echo $ID$VERSION_ID) curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.repo | sudo tee /etc/yum.repos.d/nvidia-docker.repo2、安装 NVIDIA Container Toolkit:
sudo yum install -y nvidia-container-toolkit
3、重启 Docker 服务:sudo systemctl restart docker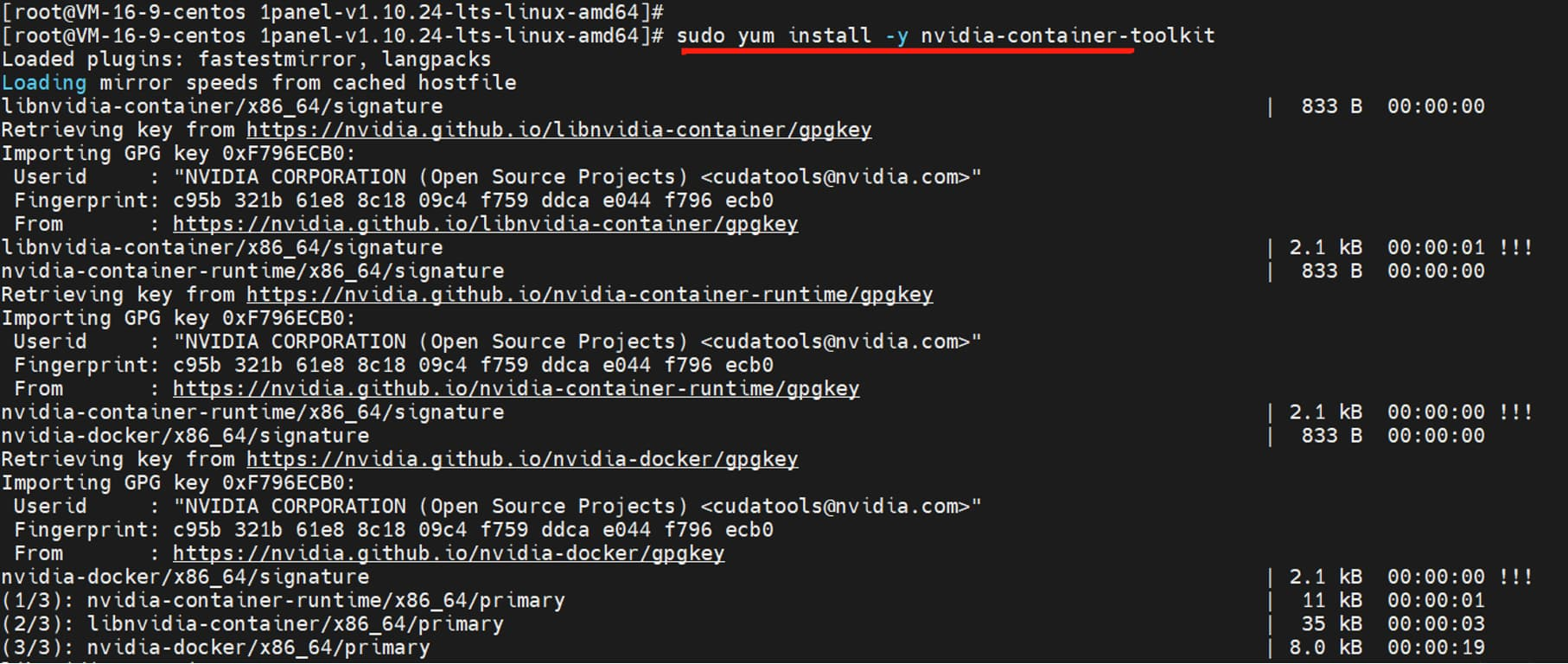
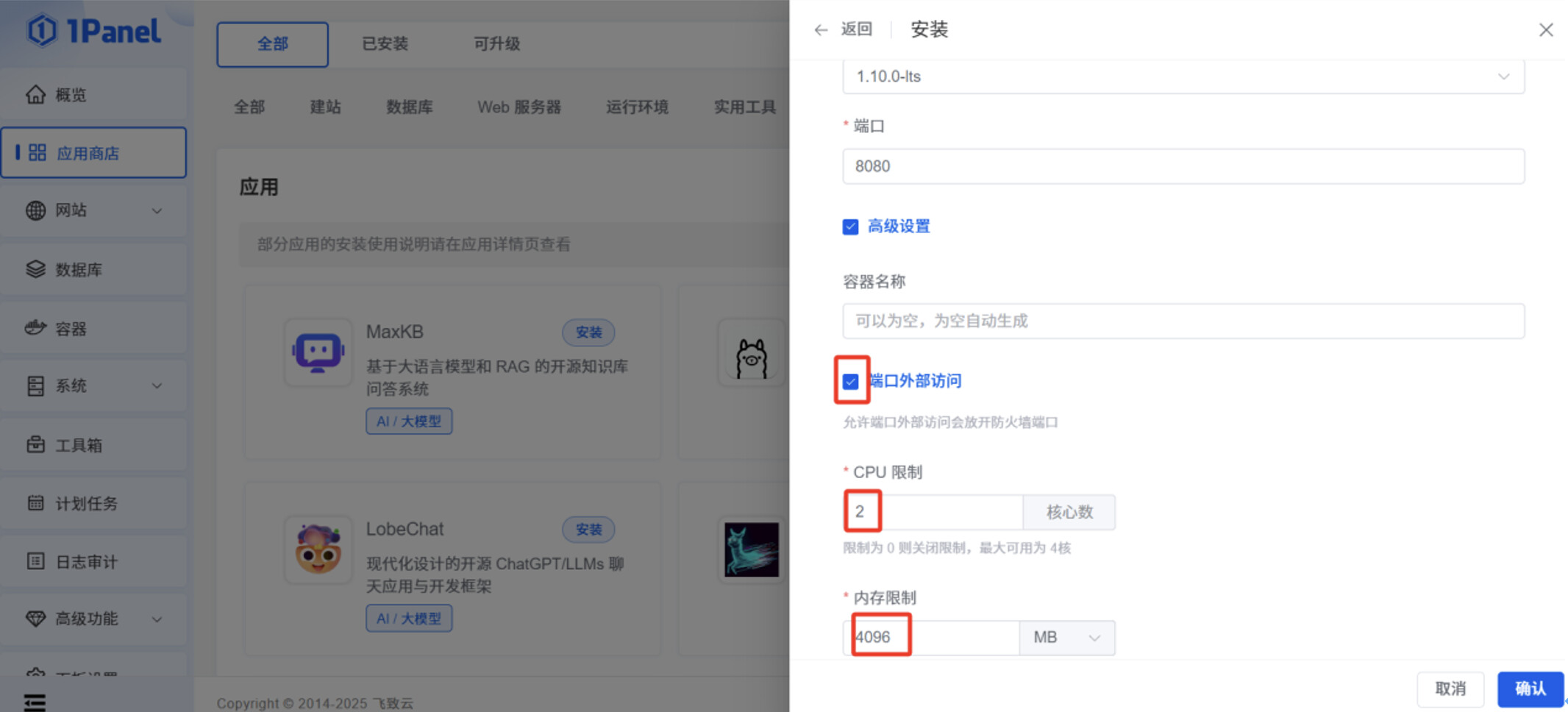
打开“端口外部访问”。
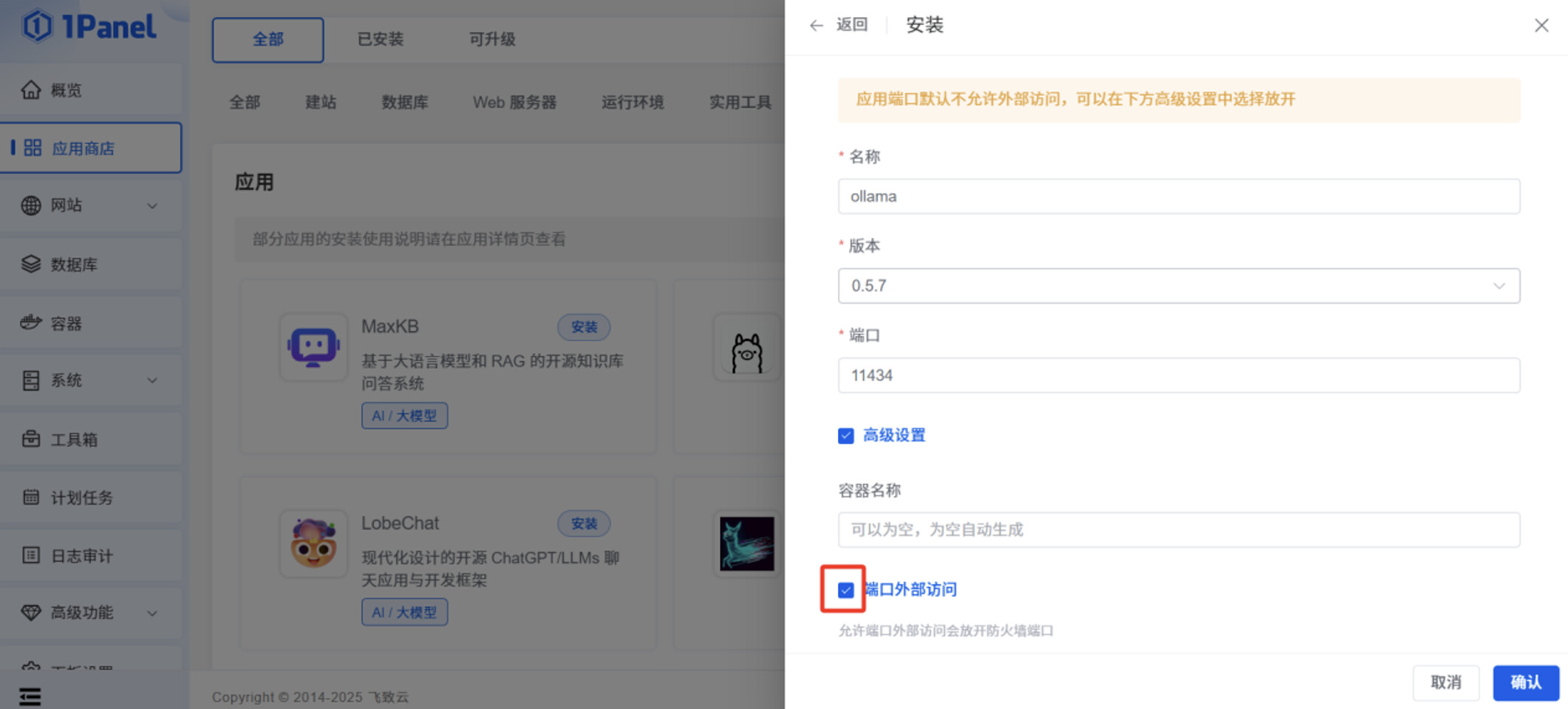
勾选”编辑 compose 文件”,将以下文本内容粘贴到输入框,此文件作用是,让 Ollama 容器在启动时,可以调用服务器本身的 GPU 资源。
networks: 1panel-network: external: true services: ollama: container_name: ${CONTAINER_NAME} deploy: resources: limits: cpus: ${CPUS} memory: ${MEMORY_LIMIT} reservations: devices: - driver: nvidia count: all capabilities: [gpu] image: ollama/ollama:0.5.7 labels: createdBy: Apps networks: - 1panel-network ports: - ${HOST_IP}:${PANEL_APP_PORT_HTTP}:11434 restart: unless-stopped tty: true volumes: - ./data:/root/.ollama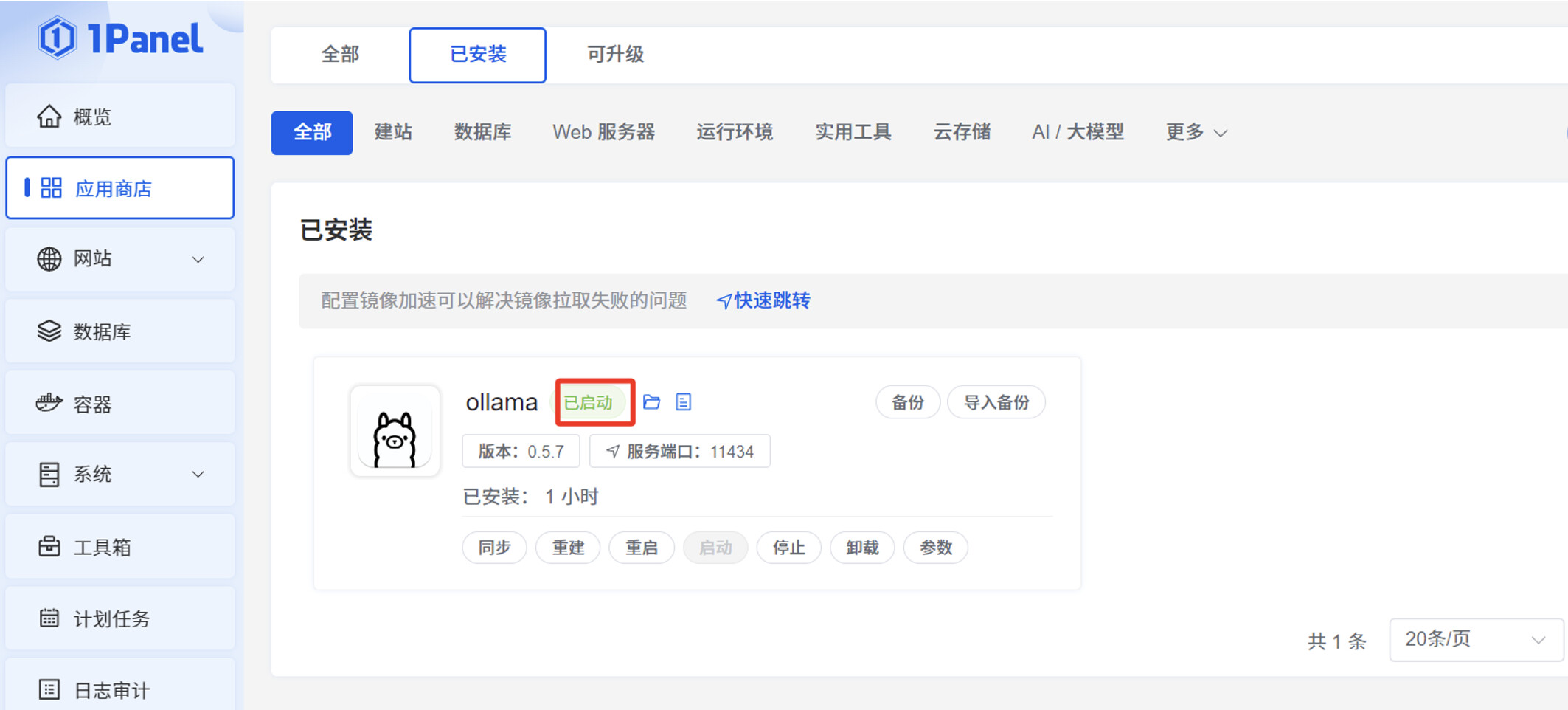
浏览器访问服务器 IP:11434,可以看到 “Ollama is running” 的显示信息。
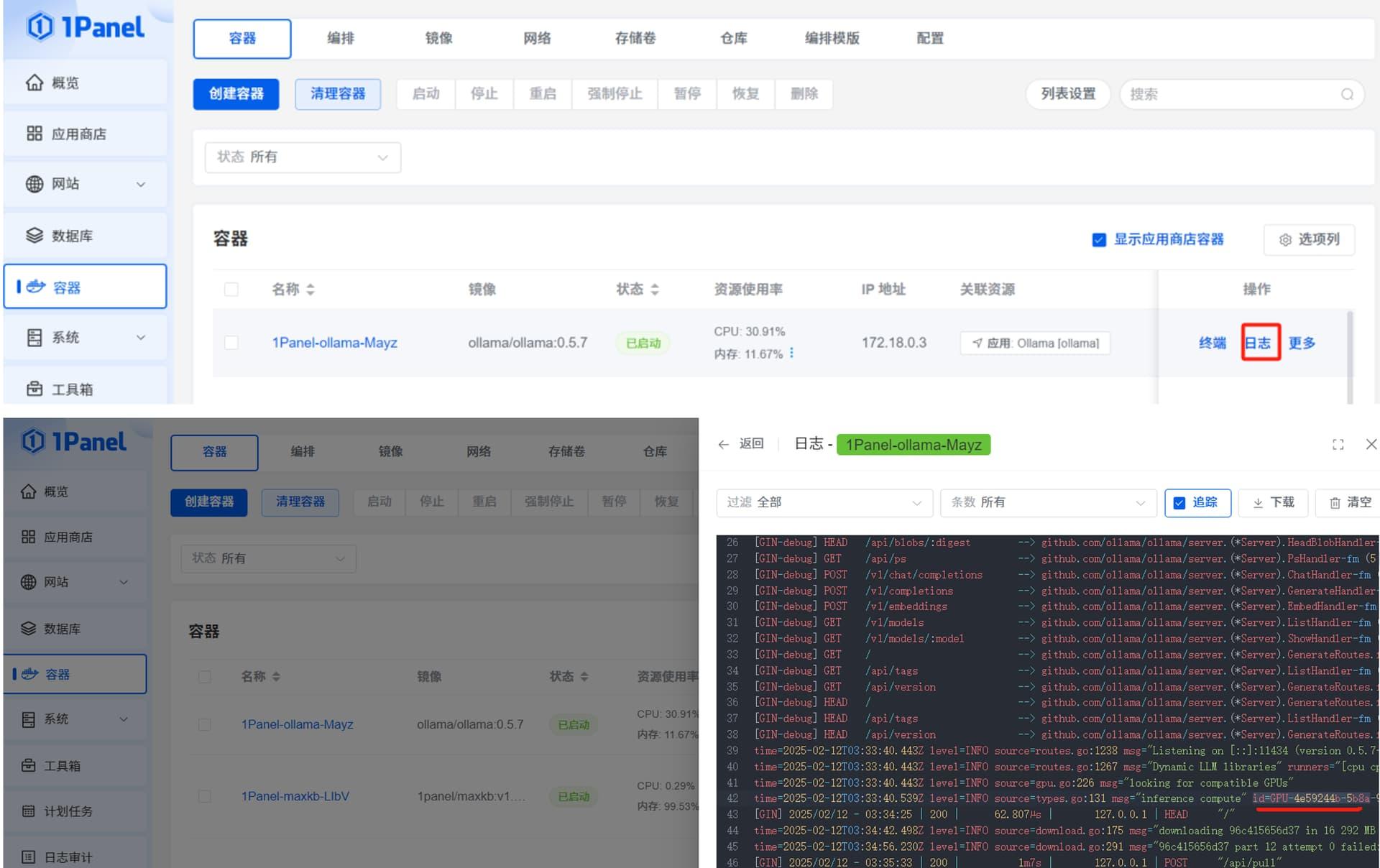
点击“容器”菜单的“终端”操作,再点击“连接”,进入 Ollama 容器的终端命令行。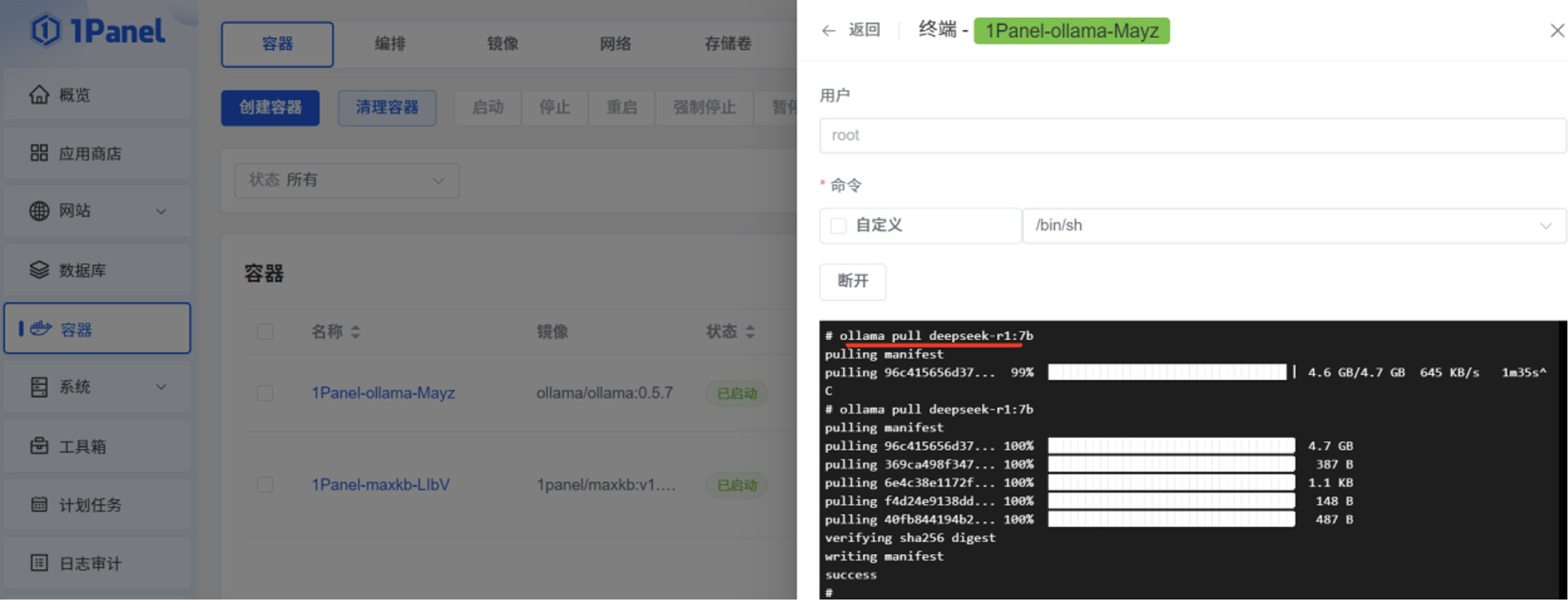
由于 Ollama 官网的网速限制,ollama pull 执行过程中,deepseek-r1:7b 安装包下载速度会持续降低,可以通过 ctrl+c 中断命令,再次执行 ollama pull deepseek-r1:7b 命令,下载速度会慢慢恢复正常。这个操作过程可能会持续多次。
2.4 第四步:安装MaxKB
在 1Panel 页面的“应用商店”,切换到“AI 大模型”,点击 MaxKB 的“安装”按钮。
点击“确认”后,可以看到 MaxKB 应用是“已启动”状态。
2.5 第五步:对接 DeepSeek -R1 模型
在 MaxKB “模型设置”菜单,点击“添加模型”。
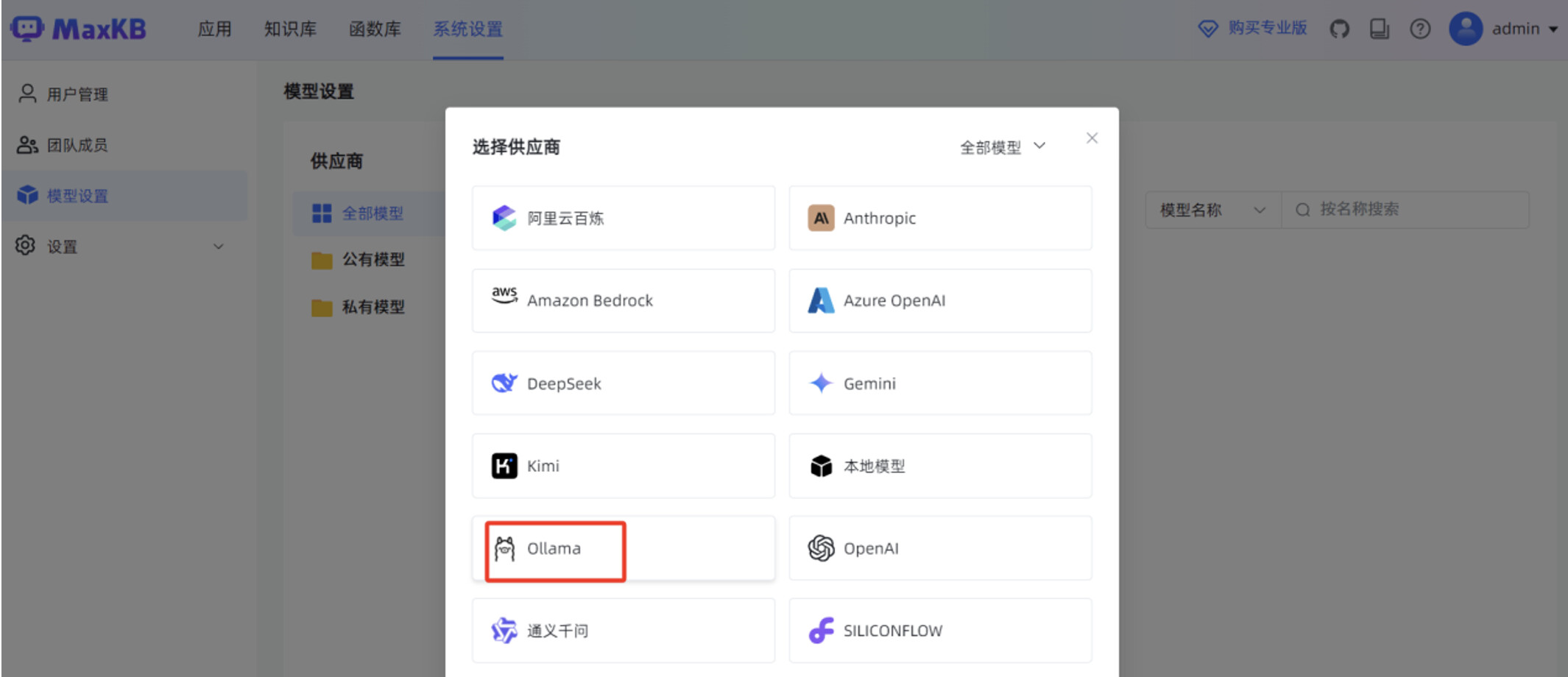
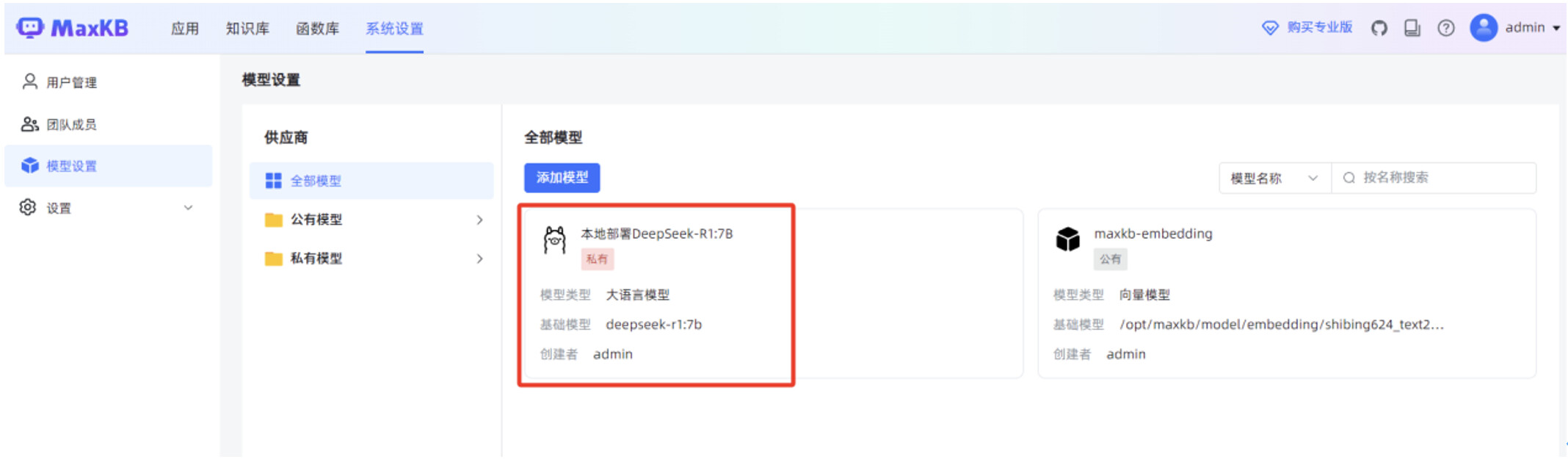
填写“基础信息”,包括“模型名称”,“模型类型”为“大语言模型”,“基础模型”为 “deepseek-r1:7b”,”API URL ”为 http://腾讯云服务器IP:11434/
2.6 第六步:发布本地AI知识库
2.6.1 简单应用发布
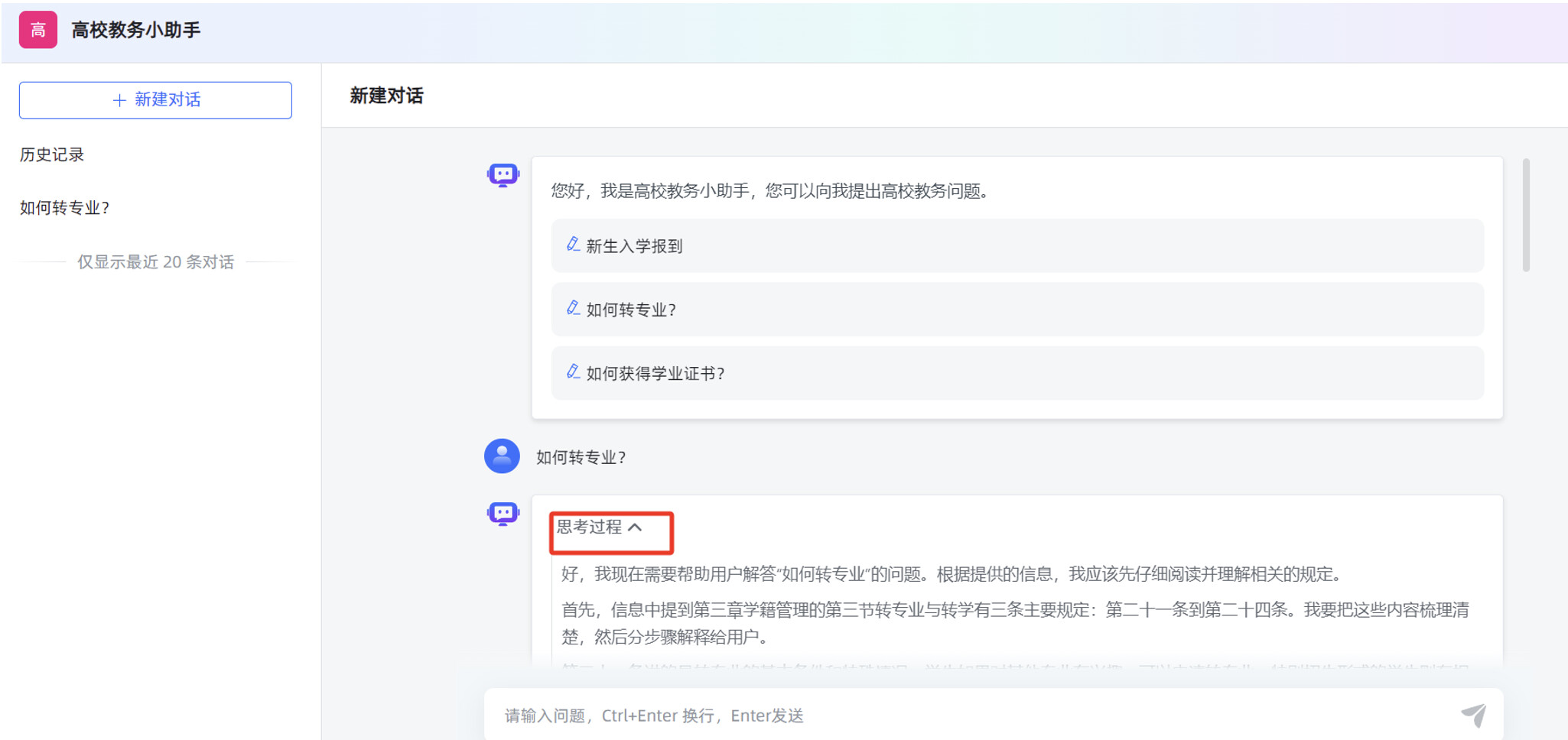
首先发布一个简单应用,使用某高校教务管理文档为例,使用 MaxKB 创建的对话应用,完成教务问题的智能对话问答。
在 MaxKB “知识库”菜单,点击“创建知识库”。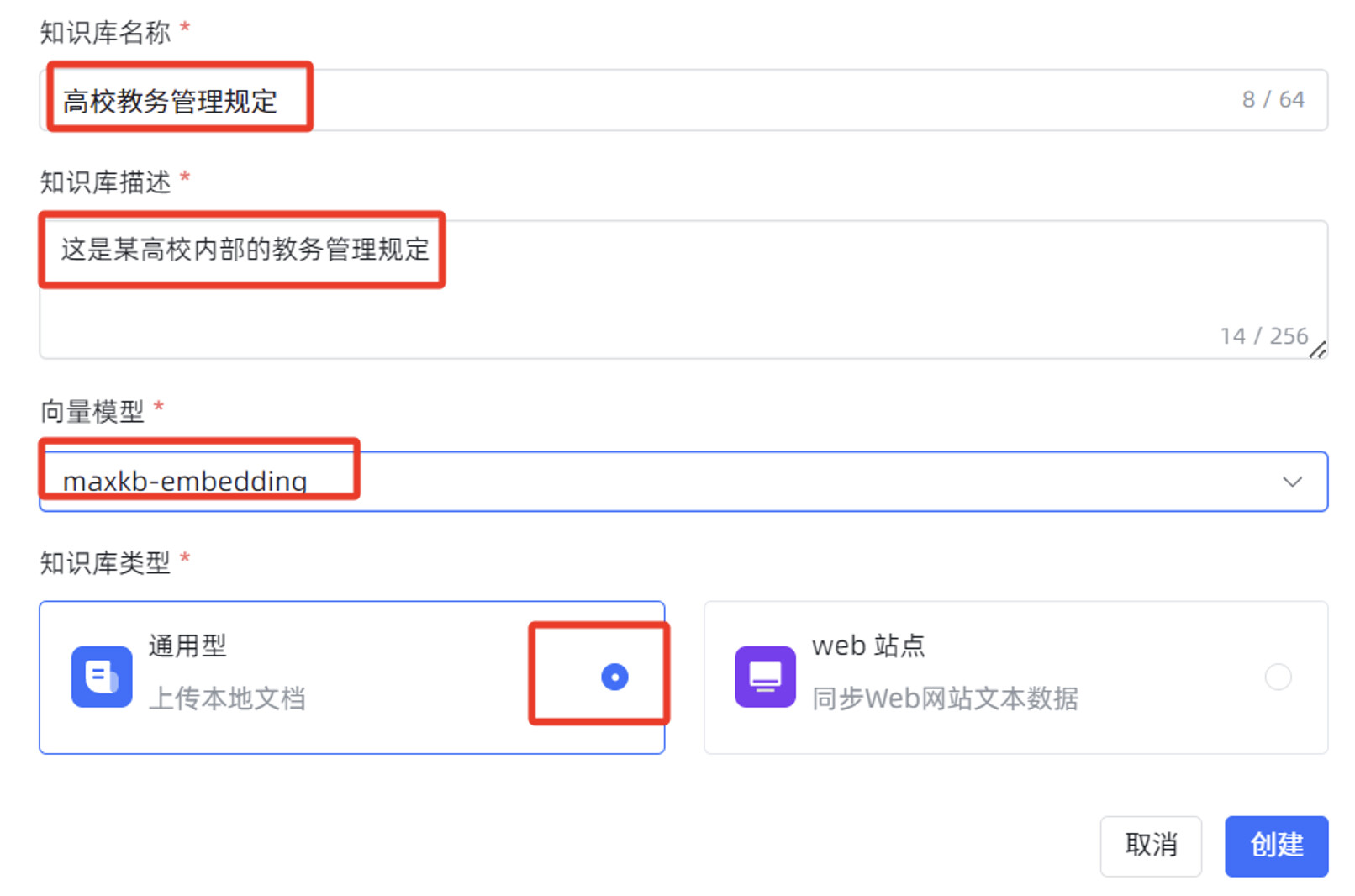
在跳转后的页面,点击“上传文档”。
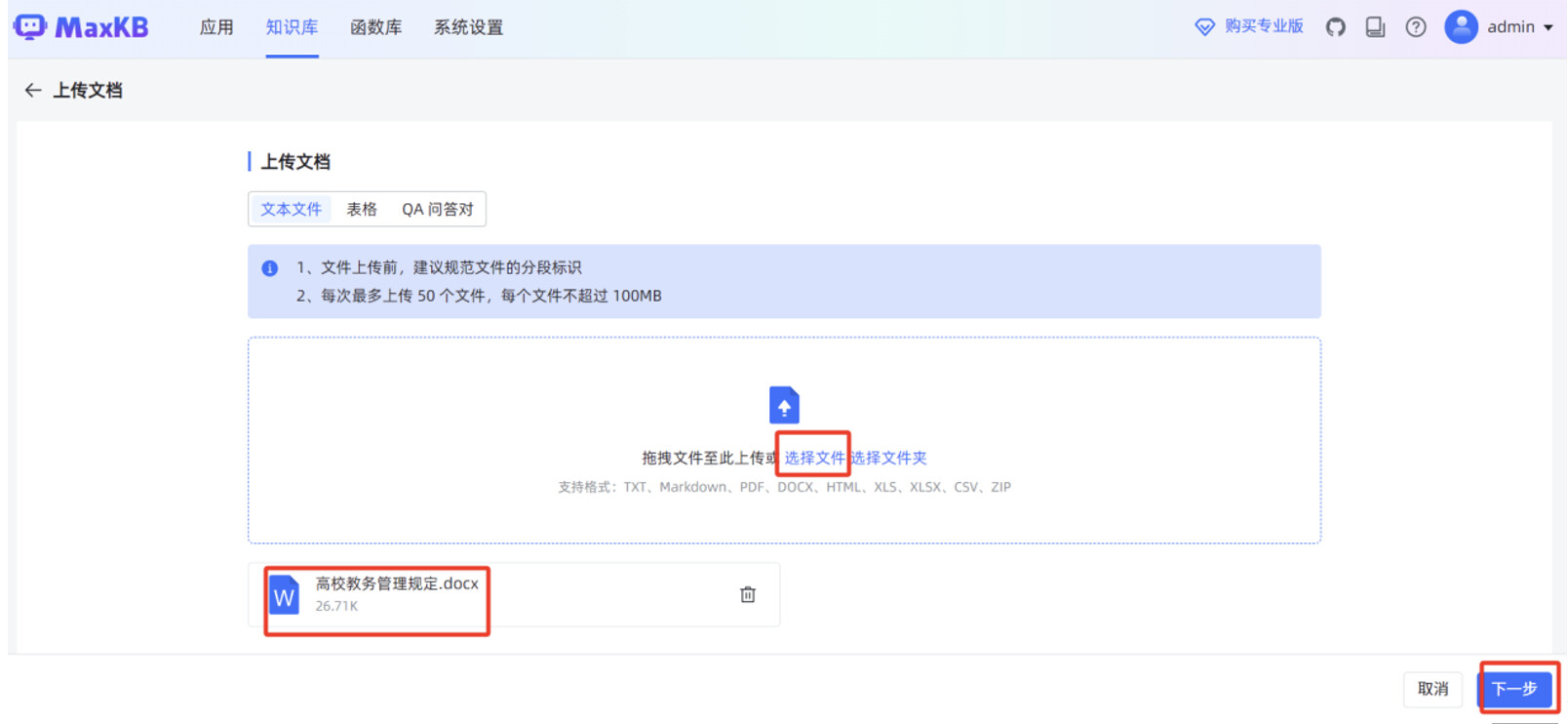
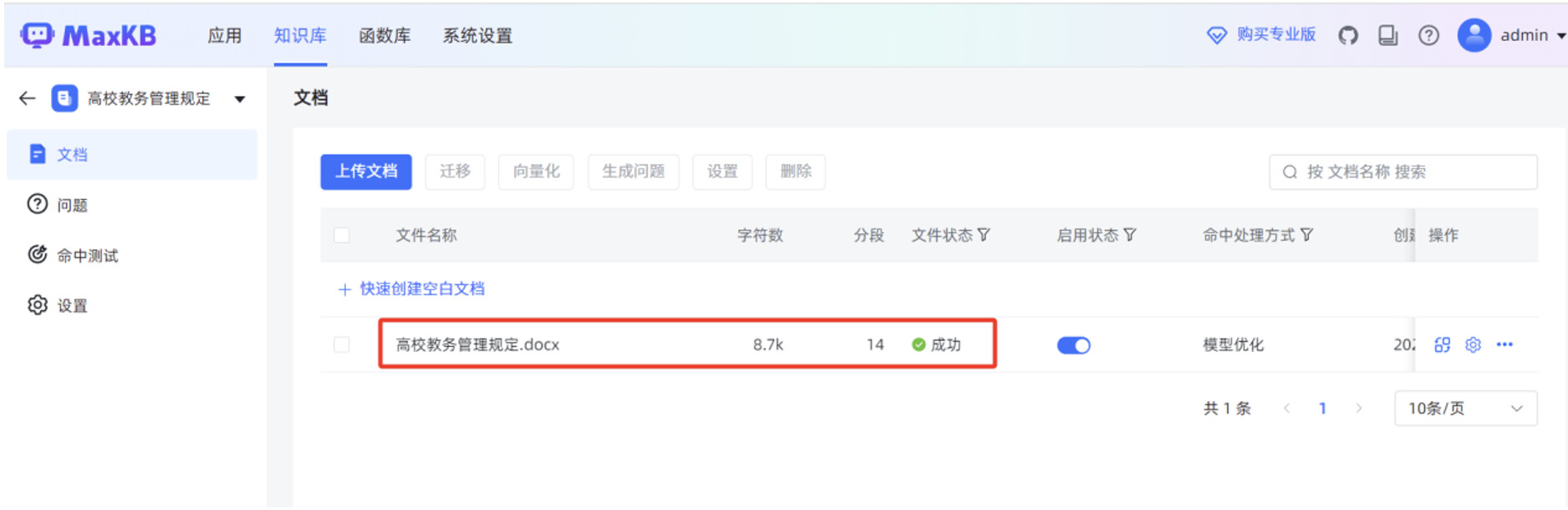
分段规则默认使用“智能分段”,点击“开始导入”。
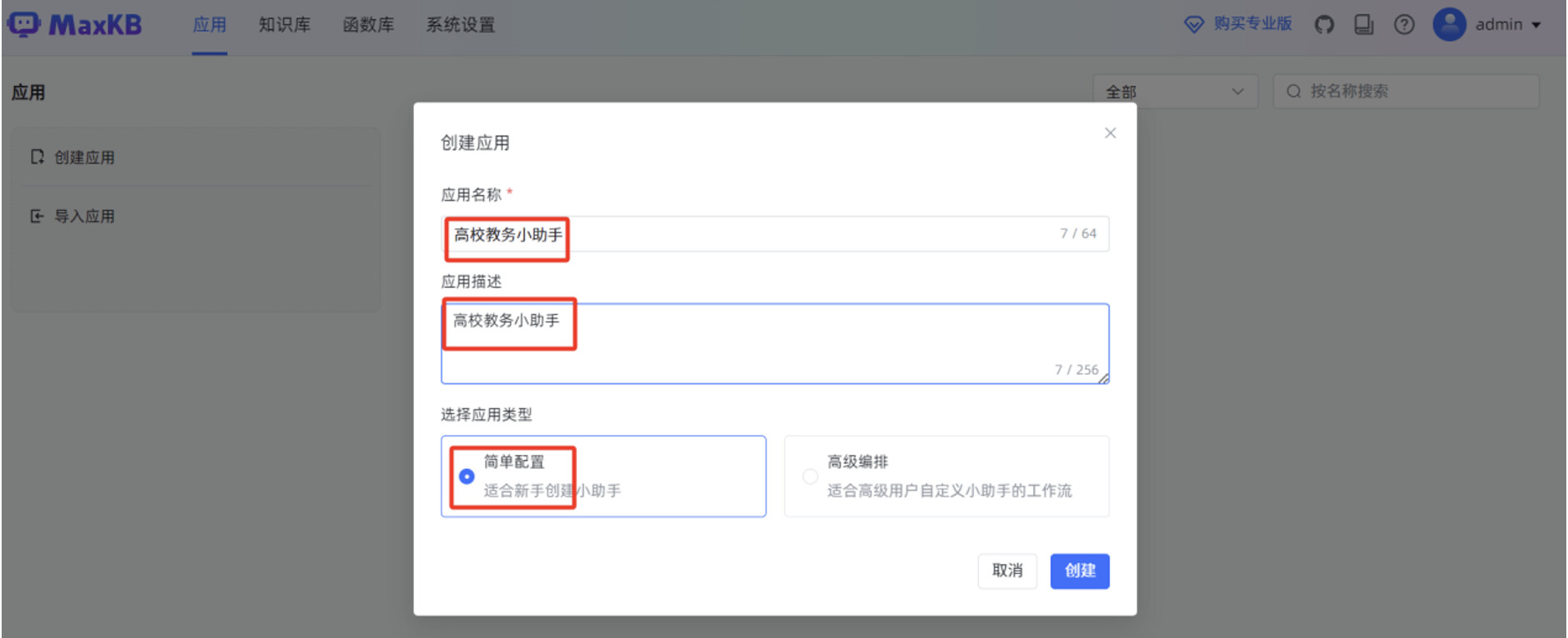
开始手动创建简单应用,在 MaxKB “应用”菜单,点击“创建应用”。
设置“AI 模型”为 MaxKB 刚才对接的 deepseek-r1:7b 本地大模型,填写“系统角色”。
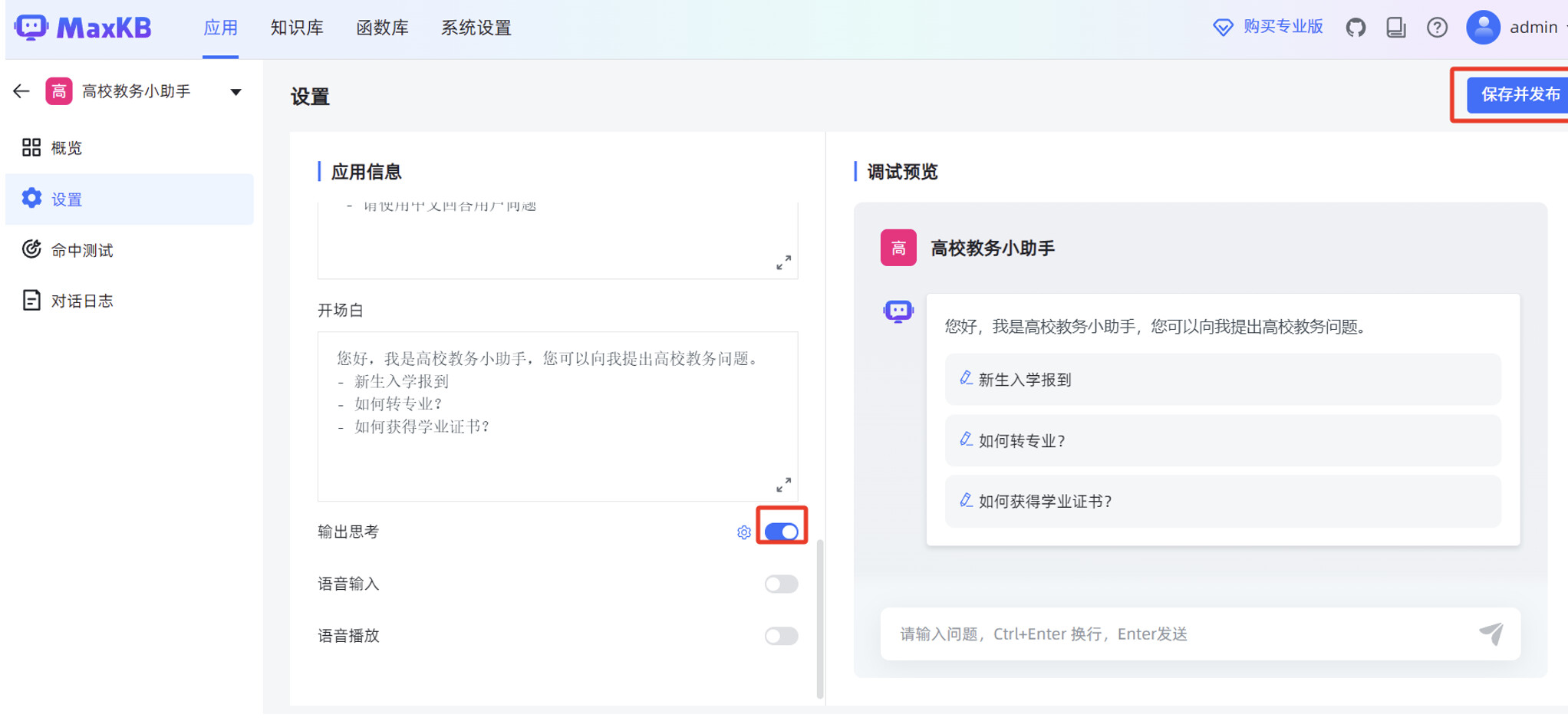
在 MaxKB “应用”菜单的概览页面,点击“演示”,可以测试 MaxKB 创建的智能对话应用。
2.6.2 高级编排应用发布
接下来,发布一个高级编排应用,使用 JumpServer 中文运维手册为例,使用 MaxKB 创建的高级应用,完成 JumpServer 运维的智能对话问答。当用户提问信息是英文时,高级应用可以将英文翻译成中文,结合 JumpServer 中文运维手册的数据,高级应用再将此中文数据自动翻译成英文,最后返回英文回复信息给用户。
工作流编排中有两个最重要的 AI 对话节点,前一个 AI 对话节点作用是把英文翻译成中文,后一个 AI 对话节点作用是把中文翻译成英文。
继续创建一个知识库,方便给工作流编排中的“AI 对话”节点使用。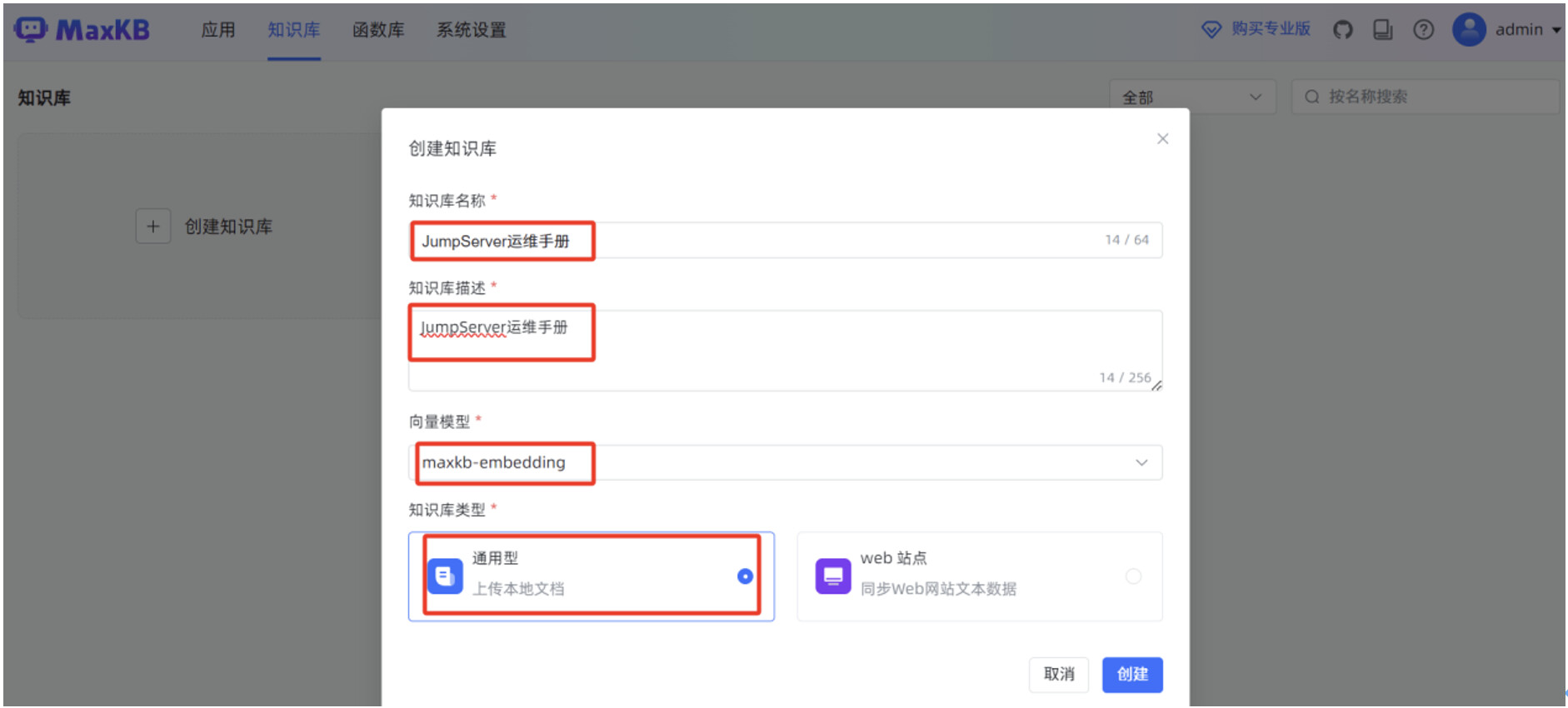
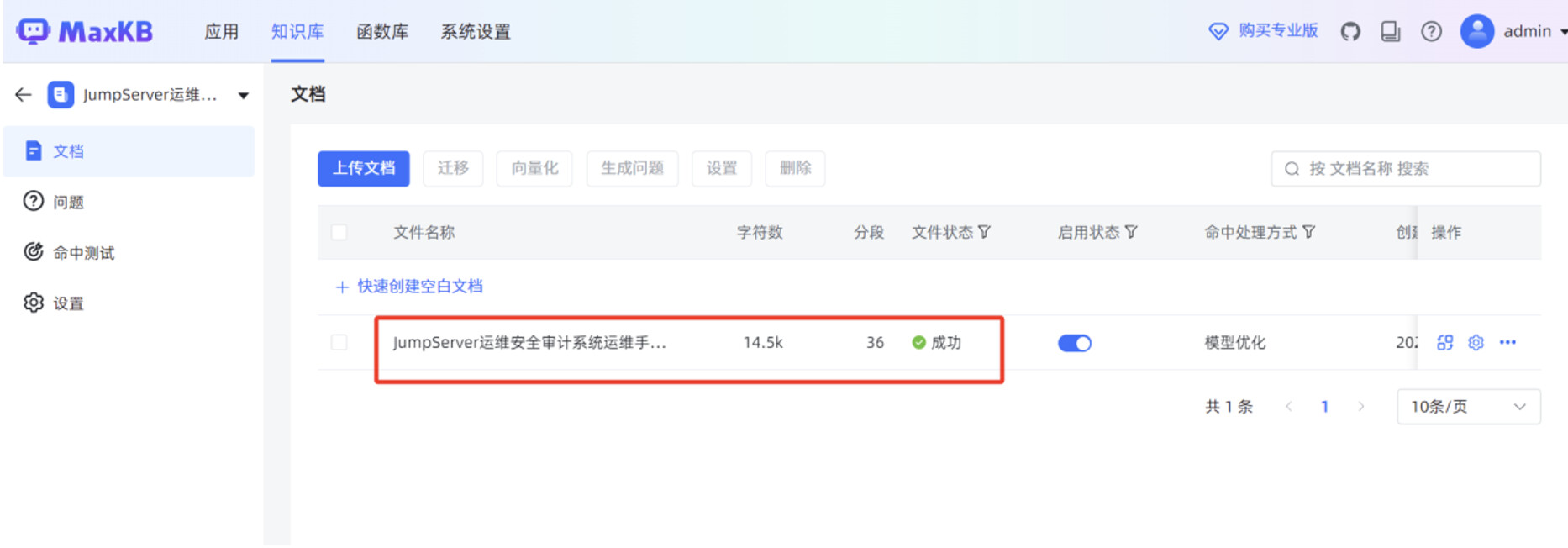
点击“选择文件”,选中本地 JumpServer 运维手册的 WORD 文件,点击“下一步”。
开始创建高级编排应用,在 MaxKB “应用”菜单,点击“导入应用”,选中本地 mk 文件,点击“确认”。
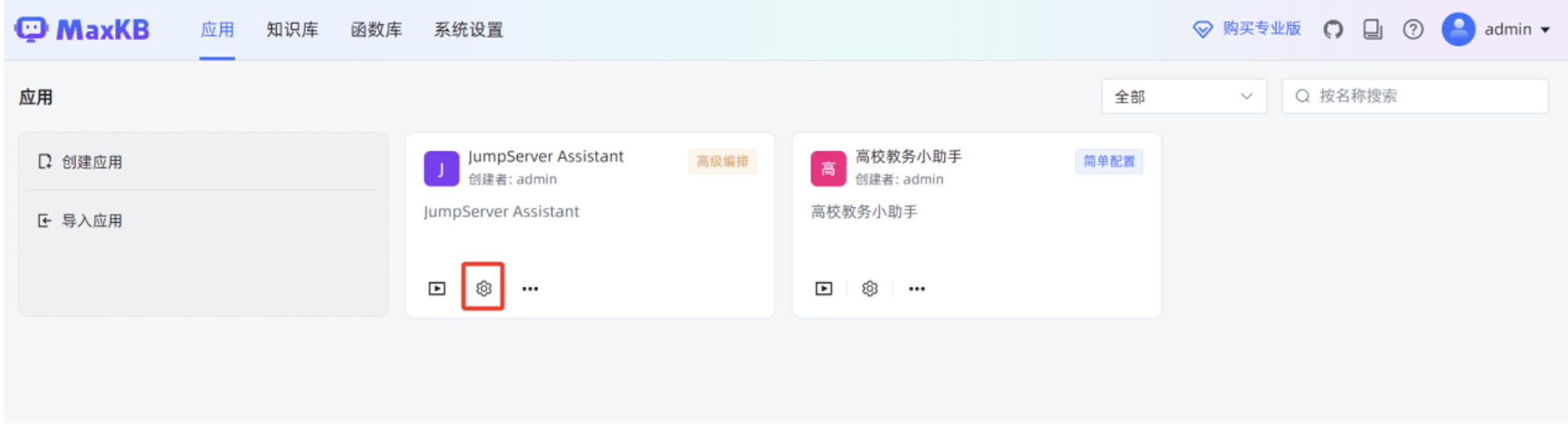
在工作流编辑页面,修改“问题翻译节点”的“AI 大模型”为本地部署的 DeepSeek-R1:7B ,“选择知识库”为刚才创建的 JumpServer 运维手册的知识库。
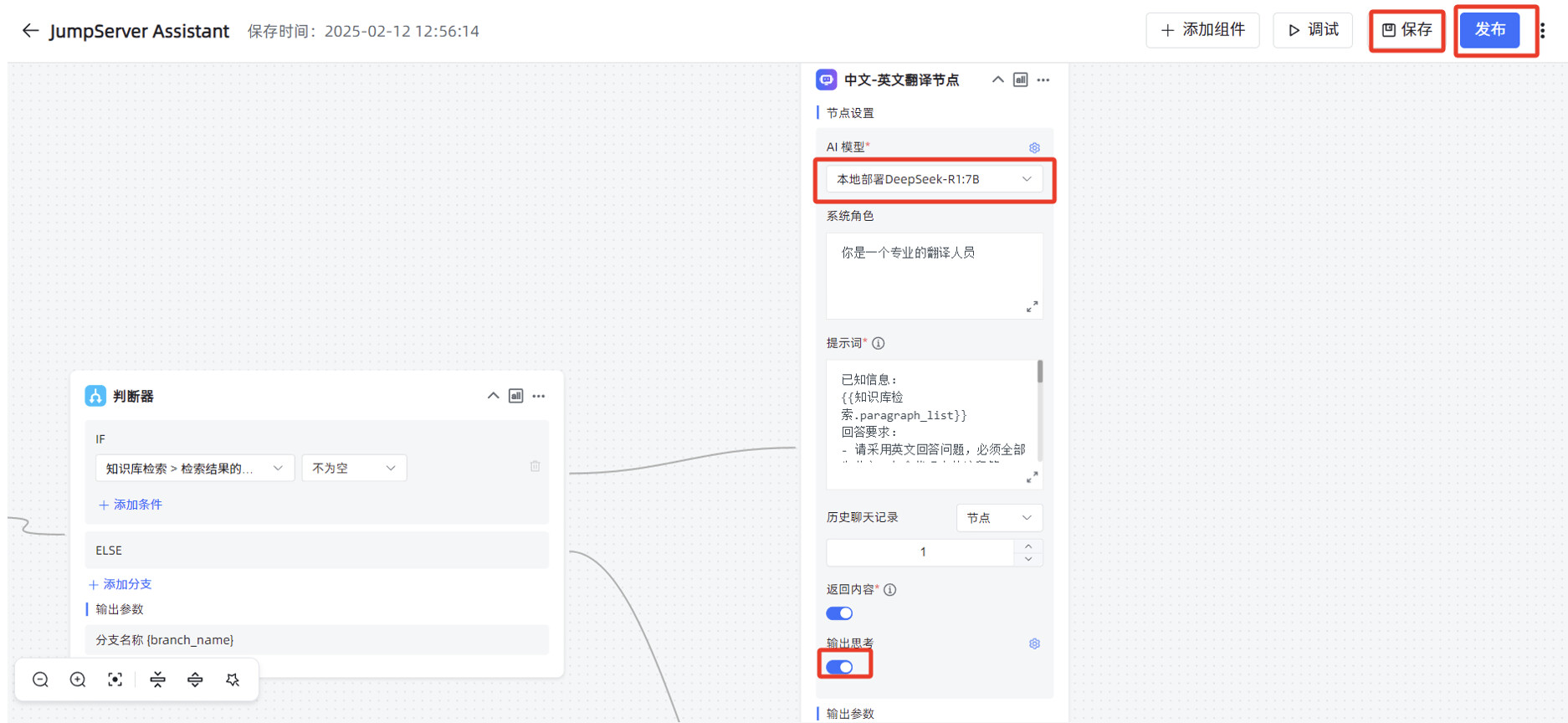
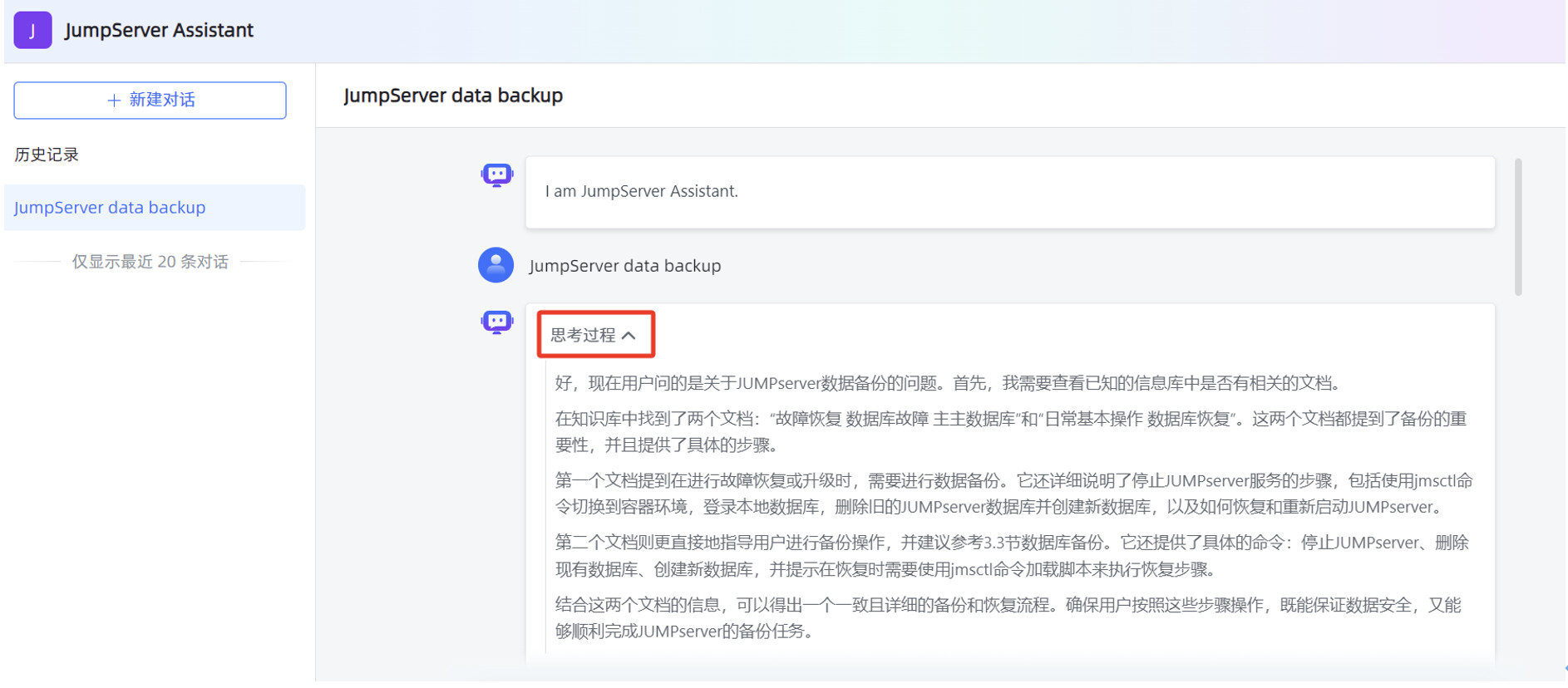
在 MaxKB “应用”菜单的概览页面,点击“演示”,可以测试 MaxKB 创建的高级编排应用。
教学视频:https://edu.fit2cloud.com/detail/l_67a3079ee4b0694c5a8b350e/4
原文链接及附件:https://bbs.fit2cloud.com/t/topic/10745/- DeepSeek+RAG 直播实操笔记;
- DeepSeek-R1+RAG 开源三件构建本地 AI 知识库教学PPT;
- JumpServer Assistant.mk
- JumpServer 运维安全审计系统运维手册.docx
- 高校教务管理规定.docx